- Continuous Subarray Sum Medium
- Longest Continous increasing subsequence Easy
- Best time to buy and sell stocks Medium
- [Best time to buy and sell stocks II] Medium
- [Best Time to Buy and Sell Stock III] Medium
- Best time to buy and sell stock with transcation fee Medium
- Insert Delete GetRandom O(1) Medium
- Product of Array Except Self Medium
- Maximum Swap Medium
- Intersection of Two Arrays Easy
- Intersection of Two Arrays II Easy
- Rectangle Overlap Easy
- Minimum Window Substring Hard
- Valid Number Hard
- Candy Hard
- Subarray Sum Equals K Medium
- Find the Kth largest item Medium
- Count Duplicates Medium
- 3 Sum Medium
- Majority Item Medium
- Diagnose Tranverse Medium
- Kth Smallest Element in a Sorted Matrix Medium
- Rotate Image Medium
- Sparse Matrix Multiplication Medium
- Search a 2D Matrix Easy
- Search a 2D Matrix II Medium
- First Bad Version Medium
- Find Minimum in Rotated Sorted Array Medium
- Divide Two Integers Medium
- Find First and Last Position of Element in Sorted Array Medium
- Reverse Linked List II Medium
- Merge K sorted List Medium
- Reorder List Medium
- Add two Number Medium
- Add two number II Medium
- Linked List Insertion Sort Medium
- Swap Nodes in Pairs Medium
- Odd Even Linked List Medium
- Insert into a Cyclic Sorted List Medium
- Rotate List Medium
- Plus One Linked List Medium
- Intersection of Two Linked Lists Medium
- Remove Duplicates from Sorted List II Medium
- Remove Nth Node From End of List Medium
- Valid Anagram Easy
- Integer to English Words Hard
- Insert five Easy
- Partition Labels Medium
- Longest Palindromic Substring Medium
- Word Break Medium
- Is Power of Four Easy
- Range Bit And Medium
- Number Complement Medium
- Single Number II Medium
- Task Scheduler Medium
- Read N Characters Given Read4 Easy
- Read N Characters Given Read4 II Hard
- Exclusive Time of Functions Medium
- Trap Rain Water Hard
- One edit distance Medium
- Pow(x,n) Medium
- Serialize and Deserialize Binary Tree Hard
- Letter Case Permutation Easy
- Excel Sheet Column Title Easy
- Valid Parentheses Easy
- Count and Say Easy
- Merge Intervals Easy
- Subsets Medium
- SubsetsII Medium
- Verifying a Alien Dictionary Medium
- Container With Most Water Medium
- Move Zeroes Medium
- Symmetric Tree Easy
- Subtree of Another Tree Medium
Big O: O(n) speed, O(1) space
Tips:
Iterate and check.
class Solution {
public:
/*
* @param A: An integer array
* @return: A list of integers includes the index of the first number and the index of the last number
*/
vector<int> continuousSubarraySum(vector<int> &A) {
// write your code here
int start = 0;
int end = start;
int sum = 0;
int ans = INT_MIN;
vector<int> ret(2, 0);
if (A.size() < 2)
return {0, 0};
for (int i = 0; i < A.size(); i++) {
if (sum < 0) {
sum = A[i];
start = end = i;
} else {
sum += A[i];
end = i;
}
if (sum > ans) {
ret[0] = start;
ret[1] = end;
ans = sum;
}
}
return ret;
}
};Big O: O(n) speed, O(1) space
Tips:
从左到右求出最长递增和最长递减。
class Solution {
public:
/**
* @param A an array of Integer
* @return an integer
*/
int longestIncreasingContinuousSubsequence(vector<int>& A) {
// Write your code here
int max = 1, s = 1, l = 1;
int len = A.size();
if (len == 0)
return 0;
for (int i = 1; i < len; ++i) {
if (A[i] > A[i-1])
s += 1;
else {
if (s > max) max = s;
s = 1;
}
if (A[i] < A[i-1])
l += 1;
else {
if (l > max) max = l;
l = 1;
}
}
if (s > max) max = s;
if (l > max) max = l;
return max;
}
};Big O: O(n) speed, O(1) space
Tips:
Record the min_prices and calculate the max profit along the way
class Solution {
public:
/**
* @param prices: Given an integer array
* @return: Maximum profit
*/
int maxProfit(vector<int> &prices) {
// write your code here
int min_price = INT_MAX;
int profit = 0;
for (int i = 0; i < prices.size(); i++) {
min_price = min(prices[i], min_price);
profit = max(prices[i] - min_price, profit);
}
return profit;
}
};Big O: O(n) speed, O(1) space
Tips:
Buy low sell High!!!! YOLO WSB!!
class Solution {
public:
/**
* @param prices: Given an integer array
* @return: Maximum profit
*/
int maxProfit(vector<int> &prices) {
// write your code here
int profit = 0;
int min_price = INT_MAX;
for (auto p : prices) {
min_price = min(min_price, p);
if (p > min_price) {
profit += (p - min_price);
min_price = p;
}
}
return profit;
}
};Big O: O(n) speed, O(1) space
Tips:
class Solution {
public:
/**
* @param prices: Given an integer array
* @return: Maximum profit
*/
int maxProfit(vector<int> &prices) {
if (prices.size() == 0) {
return 0;
}
vector<int> profit(prices.size());
int buy = 0;
buy = prices[0];
profit[0] = 0;
for (int i = 1; i < prices.size(); i++) {
profit[i] = max(profit[i - 1], prices[i] - buy);
buy = min(buy, prices[i]);
}
int sell = prices[prices.size() - 1];
int best = 0;
for (int i = prices.size() - 2; i >= 0; i--) {
best = max(best, sell - prices[i] + profit[i]);
sell = max(sell, prices[i]);
}
return best;
}
};Big O: O(n) speed, O(1) space
Tips:
class Solution {
public:
/**
* @param prices: a list of integers
* @param fee: a integer
* @return: return a integer
*/
int maxProfit(vector<int> &prices, int fee) {
// write your code here
int cash = 0, hold = -prices[0];
for (int i = 0; i < prices.size(); i++) {
cash = max(cash, hold + prices[i] - fee);
hold = max(hold, cash-prices[i]);
}
return cash;
}
};Big O: O(n*m) speed, O(man(n, m)) space
Tips:
class Solution {
public:
/**
* @param matrix: a 2D array
* @return: return a list of integers
*/
vector<int> findDiagonalOrder(vector<vector<int>> &matrix) {
int rows = matrix.size();
if (rows == 0)
return vector<int>();
int cols = matrix[0].size();
if (cols == 0)
return vector<int>();
int dig_size = rows + cols - 1;
vector<int> ret;
int i = 0, j = 0;
for (int k = 1; k <= dig_size; k++) {
vector<int> diag{};
i = k >= rows ? rows-1 : k-1;
j = k >= rows ? k-rows : 0;
while(i >= 0 && j < cols) {
diag.push_back(matrix[i][j]);
i--;
j++;
}
if (k%2 == 0)
reverse(diag.begin(), diag.end());
ret.insert(ret.end(), diag.begin(), diag.end());
}
return ret;
}
};Big O: O(n) speed, O(1) space
Tips:
The maximum number of tasks is 26. Let's allocate an array frequencies of 26 elements to keep the frequency of each task.
Iterate over the input array and store the frequency of task A at index 0, the frequency of task B at index 1, etc.
Find the maximum frequency: f_max = max(frequencies).
Find the number of tasks which have the max frequency: n_max = frequencies.count(f_max).
If the number of slots to use is defined by the most frequent task, it's equal to (f_max - 1) * (n + 1) + n_max.
Otherwise, the number of slots to use is defined by the overall number of tasks: len(tasks).
Return the maximum of these two: max(len(tasks), (f_max - 1) * (n + 1) + n_max).
class Solution {
public:
int cnt[26], maxcnt = 0, e = 0;
int leastInterval(vector<char>& tasks, int n) {
for (char c : tasks) cnt[c-'A']++;
for (int i = 0; i < 26; i++) maxcnt = max(maxcnt, cnt[i]);
for (int i = 0; i < 26; i++)
if (cnt[i] == maxcnt) e++;
return max(tasks.size(), (maxcnt-1)*(n+1) + e);
}
};
// approach 2
class Solution {
public:
int leastInterval(string &tasks, int n) {
// write your code here
unordered_map<char,int>mp;
int count = 0;
for(auto e : tasks) {
mp[e]++;
count = max(count, mp[e]);
}
int ans = (count - 1) * (n + 1);
for(auto e : mp) {
if(e.second == count) {
ans ++;
}
}
return max((int)tasks.size(), ans);
}
};**
Big O: O(n) speed, O(n) space
Tips:
When remove, swap the value at the desired location with the last item in the vector and update the index map.
class RandomizedSet {
public:
unordered_map<int, int >mp;
vector<int>vc;
int n;
/** Initialize your data structure here. */
RandomizedSet() {
srand(time(NULL));
n = 0;
}
/** Inserts a value to the set. Returns true if the set did not already contain the specified element. */
bool insert(int val) {
if (mp.find(val) == mp.end()) {
if (n < vc.size()) {
vc[n] = val;
} else {
vc.push_back(val);
}
mp[val] = n;
n++;
return true;
}
return false;
}
/** Removes a value from the set. Returns true if the set contained the specified element. */
bool remove(int val) {
if (mp.find(val) != mp.end()) {
vc[mp[val]] = vc[n-1];
mp[vc[n-1]] = mp[val];
n--;
mp.erase(val);
return true;
}
return false;
}
/** Get a random element from the set. */
int getRandom() {
if (n < 1)
return 0;
return vc[rand()%n];
}
};Big O: O(n) speed, O(1) space
Tips:
Keep a product array. Kind like a two pointer approach.
vector<int> productExceptSelf(vector<int> &nums) {
// write your code here
int n = nums.size();
vector<int>res = vector<int>(n, 0);
res[0] = 1;
for (int i = 1; i < n; i++) {
res[i] = res[i - 1] * nums[i - 1];
}
int right = 1;
for (int i = n - 1; i >= 0; i--) {
res[i] *= right;
right *= nums[i];
}
return res;
}
};Big O: O(log(m*n)) speed, O(1) space
Tips:
Binary search in all elements. Calculate the matrix coordinates.
class Solution {
public:
bool searchMatrix(vector<vector<int>> &matrix, int target) {
// write your code here
int row = matrix.size();
int col = matrix[0].size();
if (row == 0 && col == 0) {
return false;
}
int st, end;
st = 0;
end = row * col-1;
while (st <= end) {
int mid = st + (end-st)/2;
int x = mid/col;
int y = mid%col;
if (matrix[x][y] == target) {
return true;
} else if (matrix[x][y] < target) {
st = mid + 1;
} else {
end = mid - 1;
}
}
return false;
}
};Big O: O(n) speed, O(1) space
Tips:
Start from Bottom left and search to the upper right.
class Solution {
public:
int searchMatrix(vector<vector<int>> &matrix, int target) {
// write your code here
int occur = 0;
int row = matrix.size();
int col = matrix[0].size();
if (row == 0)
return occur;
int x = row-1;
int y = 0;
while (x >= 0 && y < col) {
int val = matrix[x][y];
if (val == target) {
occur ++;
x --;
} else if (val > target) {
x--;
} else {
y ++;
}
}
return occur;
}
};Big O: O(log(n)) speed, O(1) space
Tips:
Binary search from the end.
class Solution {
public:
int findFirstBadVersion(int n) {
// write your code here
int st = 1;
int end = n;
while (st < end) {
int mid = st + (end - st)/2;
if (SVNRepo::isBadVersion(mid))
end = mid;
else {
st = mid + 1;
}
}
return end;
}
};Big O: O(log(n)) speed, O(1) space
Tips:
Binary Search
class Solution {
public:
int findMin(vector<int> &nums) {
// write your code here
int st = 0;
int end = nums.size()-1;
if (nums.size() < 1)
return -1;
while (st < end) {
int mid = st + (end - st)/2;
if (nums[end] > nums[st]) {
end = mid;
} else {
if (nums[mid] < nums[st])
end = mid;
else
st = mid + 1;
}
}
return nums[end];
}
};Big O: O(log(n)) speed, O(1) space
Tips:
Binary Search but be careful of overflow and special cases.
class Solution {
public:
int divide(int dividend, int divisor) {
// write your code here
if (dividend == INT_MIN && divisor == -1)
return INT_MAX;
if (abs(divisor) == 1)
return divisor == 1 ? dividend : -dividend;
long dividend_long = dividend;
long divisor_long = divisor;
if (dividend_long == 0 || (abs(dividend_long) < abs(divisor_long)))
return 0;
int sign = (dividend_long < 0 && divisor_long > 0) || (dividend_long > 0 && divisor_long < 0);
dividend_long = abs(dividend_long);
divisor_long = abs(divisor_long);
int quo = 0;
int mul = 0;
while (dividend_long > 0) {
long divi = divisor_long << mul;
if (dividend_long >= divi) {
dividend_long -= divi;
quo += 1<<mul;
mul++;
if (dividend_long < divisor_long)
break;
} else {
mul = 0;
}
}
return sign ? -quo : quo;
}
};Big O: O(n*n) speed, O(1) space
Tips:
Min head priority queue solution.
class Solution {
public:
int kthSmallest(vector<vector<int>>& matrix, int k) {
priority_queue<int> mxheap;
for(auto x:matrix)
{
for(auto y:x)
{
if(mxheap.size()<k) mxheap.push(y);
else
{
if(y<mxheap.top())
{
mxheap.pop();
mxheap.push(y);
}
}
}
}
return mxheap.top();
}
};Big O: O(log(n)) speed, O(1) space
Tips:
Do binary search twice, First for head, second for the tail.
class Solution {
public:
vector<int> searchRange(vector<int> &nums, int target) {
// Write your code here.
int st = 0;
int end = nums.size() - 1;
vector<int> ans = {-1, -1};
while(st < end) {
int mid = st + (end-st)/2;
if (nums[mid] >= target)
end = mid;
else
st = mid + 1;
}
if (nums[end] != target)
return ans;
ans[0] = st;
st = 0;
end = nums.size() - 1;
while(st < end-1) {
int mid = st + (end-st)/2;
if (nums[mid] <= target)
st = mid;
else
end = mid;
}
ans[1] = nums[end] == target ? end : st;
return ans;
}
};Big O: O(n) speed, O(1) space
Tips:
Reverse Linked list.
class Solution {
public:
ListNode* reverseBetween(ListNode* head, int left, int right) {
ListNode dummy;
dummy.next = head;
ListNode *pre_left;
ListNode *left_tail;
ListNode *tmp = &dummy, *pre, *cur;
int count = 0;
while(tmp) {
if (count == left - 1) {
pre_left = tmp;
left_tail = tmp->next;
cur = left_tail;
pre = nullptr;
tmp = tmp->next;
} else if (count >= left && count <= right) {
ListNode *nxt = cur->next;
cur->next = pre;
pre = cur;
cur = nxt;
if (count == right) {
left_tail->next = cur;
pre_left->next = pre;
}
tmp = cur;
} else {
tmp = tmp->next;
}
count ++;
}
return dummy.next;
}
};Big O: O(nlog(k)) speed, O(n) space
Tips:
Use a priority queue to record the smallest item in the queue. Pop it and then push the next item in the list. The comparison cost will be reduced to O(logk) for every pop and insertion to priority queue. But finding the node with the smallest value just costs O(1)O(1) time.
Approach 2: Merge with Divide And Conquer
Time complexity : O(Nlogk) where k is the number of linked lists.
We can merge two sorted linked list in O(n) time where nn is the total number of nodes in two lists.
Space complexity : O(1)
We can merge two sorted linked lists in O(1)O(1) space.
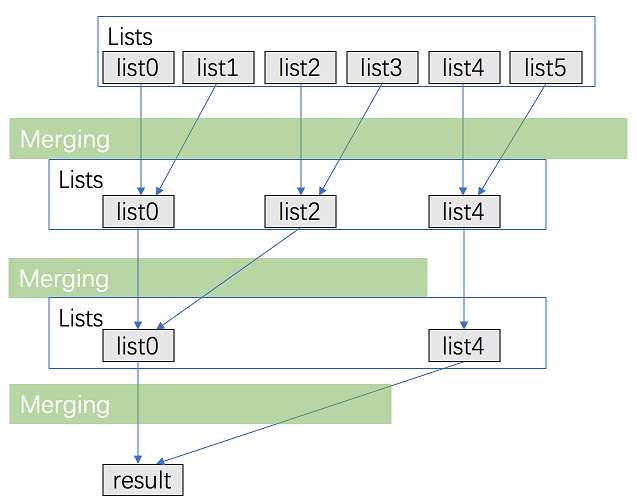
class Solution {
public:
struct compare {
bool operator()(ListNode* A, ListNode* B) {
return A->val > B->val;
}
};
ListNode *mergeKLists(vector<ListNode *> &lists) {
// write your code here
priority_queue<ListNode*, vector<ListNode*>, compare> nodes_heap;
int n = lists.size();
ListNode* ans, dummy;
dummy.next = nullptr;
for (int i = 0; i < n; i++) {
if (lists[i] != nullptr)
nodes_heap.push(lists[i]);
}
ans = &dummy;
while(!nodes_heap.empty()) {
ListNode* tmp = nodes_heap.top();
nodes_heap.pop();
ans->next = tmp;
ans = ans->next;
tmp = tmp->next;
if (tmp != nullptr)
nodes_heap.push(tmp);
}
return dummy.next;
}
};
// Approach 2 (Merge Lists one by one. O(kn) speed.)
class Solution {
public:
ListNode* merge2Lists(ListNode* l1, ListNode* l2) {
if (!l1) return l2;
if (!l2) return l1;
ListNode* head = l1->val <= l2->val? l1 : l2;
head->next = l1->val <= l2->val ? merge2Lists(l1->next, l2) : merge2Lists(l1, l2->next);
return head;
}
ListNode* mergeKLists(vector<ListNode*>& lists) {
if (lists.size() == 0) return NULL;
ListNode* head = lists[0];
for (int i = 1; i < lists.size(); i++)
head = merge2Lists(head, lists[i]);
return head;
}
};Big O: O(log(n)) speed, O(1) space
Tips:
Iteration and check or recursion.
class Solution {
public:
/**
* @param num an integer
* @return true if num is an ugly number or false
*/
bool isUgly(int num) {
if (num <= 0) return false;
if (num == 1) return true;
while (num >= 2 && num % 2 == 0) num /= 2;
while (num >= 3 && num % 3 == 0) num /= 3;
while (num >= 5 && num % 5 == 0) num /= 5;
return num == 1;
}
};Big O: O(M) speed, O(1) space
Tips:
Let M be the number of cells in the grid.
Time complexity : O(M). We perform two steps; transposing the matrix, and then reversing each row. Transposing the matrix has a cost of O(M) because we're moving the value of each cell once. Reversing each row also has a cost of O(M), because again we're moving the value of each cell once.
Space complexity : O(1) because we do not use any other additional data structures.
class Solution {
public:
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
void rotate(vector<vector<int>>& matrix) {
int rows = matrix.size();
int cols = matrix[0].size();
// transpose
for (int x = 0; x < rows; x++) {
for (int y = x + 1; y < cols; y++) {
swap(&matrix[x][y], &matrix[y][x]);
}
}
// reflect
for (int x = 0; x < rows; x++) {
int st = 0, end = cols - 1;
while (st < end) {
swap(&matrix[x][st++], &matrix[x][end--]);
}
}
}
};Big O: O(M) speed, O(1) space
Tips:
We'll count the number of 'X's and 'O's as xCount and oCount.
We'll also use a helper function win(player) which checks if that player has won. This checks the 8 horizontal, vertical, or diagonal lines of the board for if there are three in a row equal to that player.
class Solution {
public:
bool is_winner(vector<string>& board, char let) {
for (int i = 0; i < 3; i++) {
if (board[i][0] == let && board[i][1] == let && board[i][2] == let)
return true;
}
for (int i = 0; i < 3; i++) {
if (board[0][i] == let && board[1][i] == let && board[2][i] == let)
return true;
}
if (board[0][0] == let && board[1][1] == let && board[2][2] == let)
return true;
if (board[0][2] == let && board[1][1] == let && board[2][0] == let)
return true;
return false;
}
bool validTicTacToe(vector<string>& board) {
// 0 for 'X', 1 for 'O'
int xCount = 0, oCount = 0;
for (auto vec : board) {
for (auto c : vec) {
if (c == 'X') xCount ++;
if (c == 'O') oCount ++;
}
}
if (xCount == 0 && oCount == 0) return true;
if (xCount != oCount && xCount - oCount != 1) return false;
if (is_winner(board, 'X') && (oCount != xCount-1)) return false;
if (is_winner(board, 'O') && (xCount != oCount)) return false;
return true;
}
};Big O: O(n) speed, O(1) space
Tips: (Greedy)
Intuition
At each digit of the input number in order, if there is a larger digit that occurs later, we know that the best swap must occur with the digit we are currently considering.
Algorithm
We will compute last[d] = i, the index i of the last occurrence of digit d (if it exists).
Afterwards, when scanning the number from left to right, if there is a larger digit in the future, we will swap it with the largest such digit; if there are multiple such digits, we will swap it with the one that occurs the latest.
class Solution {
public:
/**
* @param num: a non-negative intege
* @return: the maximum valued number
*/
int maximumSwap(int num) {
vector<int> pos(10, -1);
string number = to_string(num);
int n = number.size();
for (int i = 0; i < n; i++) {
pos[number[i] - '0'] = i;
}
for (int i = 0; i < n; i++) {
for (char j = '9'; j > number[i]; j--) {
if (pos[j - '0'] > i) {
swap(number[i], number[pos[j - '0']]);
return stoi(number);
}
}
}
return num;
}
};
class Solution {
public:
int maximumSwap(int num) {
string num_str = to_string(num);
int n = num_str.size();
int max_val = -1, max_i = -1;
int left = -1, right = -1;
for (int i = n - 1; i >= 0; i--) {
if (num_str[i] > max_val) {
max_val = num_str[i];
max_i = i;
} else if (num_str[i] < max_val) {
left = i;
right = max_i;
}
}
if (left == -1) return num;
char c = num_str[left];
num_str[left] = num_str[right];
num_str[right] = c;
return stoi(num_str);
}
};Big O: O(nlog(n) + mlog(m)) speed, O(1) space
Sort first O(nlogn), and then iterate.
Or we can use two hash sets.
class Solution {
public:
vector<int> intersection(vector<int> &nums1, vector<int> &nums2) {
// write your code here
sort(nums1.begin(), nums1.end());
sort(nums2.begin(), nums2.end());
vector<int> ans;
int i = 0, j = 0;
while (i < nums1.size() && j < nums2.size()) {
if (nums1[i] < nums2[j]) {
i++;
} else if (nums1[i] > nums2[j]) {
j++;
} else {
ans.push_back(nums1[i]);
i++;
j++;
}
}
return ans;
}
};Big O: O(k*n^2) speed, O(1) space
Use unordered hash to record non-zero item first and only operates on these none-zero entries.
class Solution {
public:
vector<vector<int>> multiply(vector<vector<int>> &A, vector<vector<int>> &B) {
// write your code here
vector<vector<int>> ans(A.size(), vector<int>(B[0].size(), 0));
for (int i = 0; i < A.size(); i++) {
unordered_map<int, int> umap;
for (int j = 0; j < A[0].size(); j++) {
umap[j] = A[i][j];
}
for (int k = 0; k < B[0].size(); k++) {
int sum = 0;
for (auto item : umap) {
if (B[item.first][k] != 0)
sum += item.second * B[item.first][k];
}
ans[i][k] = sum;
}
}
return ans;
}
};Big O: O(1) speed, O(1) space
Intuition
If the rectangles overlap, they have positive area. This area must be a rectangle where both dimensions are positive, since the boundaries of the intersection are axis aligned.
Thus, we can reduce the problem to the one-dimensional problem of determining whether two line segments overlap.
Algorithm
Say the area of the intersection is width * height, where width is the intersection of the rectangles projected onto the x-axis, and height is the same for the y-axis. We want both quantities to be positive.
The width is positive when min(rec1[2], rec2[2]) > max(rec1[0], rec2[0]), that is when the smaller of (the largest x-coordinates) is larger than the larger of (the smallest x-coordinates). The height is similar.
class Solution {
public:
/**
* @param l1: top-left coordinate of first rectangle
* @param r1: bottom-right coordinate of first rectangle
* @param l2: top-left coordinate of second rectangle
* @param r2: bottom-right coordinate of second rectangle
* @return: true if they are overlap or false
*/
bool doOverlap(Point &l1, Point &r1, Point &l2, Point &r2) {
return (min(r1.x, r2.x) > max(l1.x, l2.x)) && (min(l1.y, l2.y) > max(r1.y, r2.y));
}
};Big O: O(K + T) speed, O(1) space, K size of s, T size of T
Tips:
Algorithm
We start with two pointers, leftleft and rightright initially pointing to the first element of the string SS.
We use the rightright pointer to expand the window until we get a desirable window i.e. a window that contains all of the characters of TT.
Once we have a window with all the characters, we can move the left pointer ahead one by one. If the window is still a desirable one we keep on updating the minimum window size.
If the window is not desirable any more, we repeat step \; 2step2 onwards.
class Solution {
public:
static string minWindow(const string &str, const string &pattern) {
// TODO: Write your code here
string ret_str = "";
unsigned int min_str = -1, win_s, win_e, match = 0;
unordered_map <char, int> umap;
for (auto chr : pattern)
umap[chr] ++;
for (win_e = win_s = 0; win_e < str.size(); win_e ++) {
if (umap.find(str[win_e]) != umap.end()) {
if (--umap[str[win_e]] == 0) {
match ++;
}
}
while (match == umap.size()) {
if ((win_e - win_s + 1) < min_str) {
min_str = min(min_str, win_e - win_s + 1);
ret_str = str.substr(win_s, win_e - win_s + 1);
}
if (umap.find(str[win_s]) != umap.end() && ++umap[str[win_s]] > 0) {
match --;
}
win_s++;
}
}
return ret_str;
}
};Big O: O(N) speed, O(1) space
Tips:
Divide and conquer. Divide it into two parts around the e/E symbol and check both sides.
class Solution {
public:
bool ojbk(string s, int k){
for(int i=0;i<s.size();i++){
if((s[i]=='+' || s[i]=='-') && i!=0) return false;
}
if(s[0]=='+' || s[0]=='-') s.erase(s.begin());
int countDot=0;
for(int i=0;i<s.size();i++){
if(s[i]=='.') countDot++;
else if(!isdigit(s[i])) return false;
}
if(s=="" || s==".") return false;
return countDot<=k;
}
bool isNumber(string s) {
while(s.size()>0 && s.back()==' ') s.pop_back();
while(s.size()>0 && s[0]==' ') s.erase(s.begin());
int countE=0;
int pos;
for(int i=0;i<s.size();i++){
if(s[i]=='e'){
countE++;
pos=i;
}
}
if(countE>=2) return false;
if(countE==0) return ojbk(s,1);
return ojbk(s.substr(0,pos),1) && ojbk(s.substr(pos+1),0);
}
};Big O: O(N) speed, O(1) space
Tips:
Hash map.
class Solution {
public:
bool isAnagram(string s, string t) {
int umap[26] = {};
if (s.size() != t.size())
return false;
for (auto &c : s)
umap[c-'a'] ++;
int count = 0;
for (auto &c : t) {
umap[c-'a'] --;
if (umap[c-'a'] < 0)
return false;
}
return true;
}
};Big O: O(N) speed, O(1) space
Tips:
Divide and conquer. Divide it into thousands and conquer it one by one.
class Solution {
public:
string thousandToWords(int num) {
string ret = "";
if (num >= 100) {
ret += digits[num/100] + "Hundred ";
num %= 100;
}
if (num == 0) return ret;
ret += (num < 20) ? digits[num] : tens[num/10] + digits[num%10];
return ret;
}
string numberToWords(int num) {
string ans = "";
if (num == 0)
return "Zero";
for (int i = 0; i < 4; i++) {
if (num >= units[i].first) {
ans += thousandToWords(num/units[i].first) + units[i].second;
num %= units[i].first;
}
}
ans += thousandToWords(num);
if (ans.size() > 0)
ans.pop_back();
return ans;
}
private:
string digits[20] = {"", "One ", "Two ", "Three ", "Four ", "Five ", "Six ", "Seven ", "Eight ", "Nine ", "Ten ", "Eleven ", "Twelve ", "Thirteen ", "Fourteen ", "Fifteen ", "Sixteen ", "Seventeen ", "Eighteen ", "Nineteen "};
string tens[10] = {"", "Ten ", "Twenty ", "Thirty ", "Forty ", "Fifty ", "Sixty ", "Seventy ", "Eighty ", "Ninety "};
pair<int, string> units[4] = { {1000*1000*1000, "Billion "}, {1000*1000, "Million "}, {1000, "Thousand "}, {100, "Hundred "}};
};Big O: O(N) speed, O(1) space
Tips:
Find mid node, reverse, and merge.
class Solution {
public:
ListNode *reverseNode (ListNode* head) {
ListNode *pre, *cur;
pre = nullptr;
cur = head;
while (cur) {
ListNode *nxt = cur->next;
cur->next = pre;
pre = cur;
cur = nxt;
}
return pre;
}
void reorderList(ListNode* head) {
if (head == nullptr || head->next == nullptr)
return;
ListNode *slow, *fast;
slow = fast = head;
while (fast && fast->next) {
slow = slow->next;
fast = fast->next->next;
}
ListNode *tail = reverseNode(slow);
ListNode *first = head;
while(tail->next != nullptr) {
ListNode *tmp = first->next;
first->next = tail;
first = tmp;
tmp = tail->next;
tail->next = first;
tail = tmp;
}
return;
}
};Big O: O(N) speed, O(1) space
Tips:
Carry ripple adder
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
int carry = 0;
ListNode dummy, *tmp;
tmp = &dummy;
while (l2 || l1 || carry) {
int sum = 0;
if (l1 && l2)
sum = (carry + l1->val + l2->val);
else if (l1 != nullptr || l2 != nullptr)
sum = (carry + ((l1) ? l1->val : l2->val));
else
sum = carry;
carry = sum/10;
ListNode *new_node = new ListNode(sum%10, nullptr);
tmp -> next = new_node;
tmp = tmp->next;
l1 = l1 ? l1->next : nullptr;
l2 = l2 ? l2->next : nullptr;
}
return dummy.next;
}
};Big O: O(N) speed, O(1) space
Tips:
Approach 1:
Reverse each list and then do add two number.
Approach 2:
Convert the number as string and then calculate from the last position.
Or use two stacks.
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
string a, b;
ListNode *result = nullptr;
while(l1) { a.push_back(l1->val+'0'); l1 = l1->next;}
while(l2) { b.push_back(l2->val+'0'); l2 = l2->next;}
int l = a.size()-1, r = b.size()-1, carry = 0;
while(l >= 0 || r >= 0 || carry == 1) {
int c = (l >= 0 ? a[l--]-'0' : 0) + ( r >= 0 ? b[r--]-'0' : 0) + carry;
ListNode *temp = new ListNode(c%10);
temp->next = result;
result = temp;
carry = c/10;
}
return result;
}
};Big O: O(N) speed, O(1) space
Tips:
Keep a separate sorted list by creating a sentinal node. Compare and insert nodes into that separate list.
class Solution {
public:
ListNode * insertionSortList(ListNode * head) {
// write your code here
ListNode sentinal, *tmp, *tmp_s;
sentinal.next = nullptr;
tmp = head;
while (tmp) {
ListNode* next = tmp->next;
tmp_s = &sentinal;
while (tmp_s->next != nullptr && tmp_s->next->val < tmp->val) {
tmp_s = tmp_s->next;
}
tmp->next = tmp_s->next;
tmp_s->next = tmp;
tmp = next;
}
return sentinal.next;
}
};Big O: O(N) speed, O(1) space
Tips:
We swap the nodes on the go. After swapping a pair of nodes, say A and B, we need to link the node B to the node that was right before A. To establish this linkage we save the previous node of node A in prevNode.
class Solution {
public:
ListNode * swapPairs(ListNode * head) {
// write your code here
if (!head || !head->next)
return head;
ListNode *l1, *l2, *pre, sentinal;
l1 = head;
pre = &sentinal;
while (l1 && l1->next) {
l2 = l1->next;
ListNode *l2_next = l2->next;
l1->next = l2_next;
l2->next = l1;
pre->next = l2;
pre = l1;
l1 = l2_next;
}
return sentinal.next;
}
};Big O: O(N) speed, O(1) space
Tips:
Construct the even and odd linked list first. Then hook the even list to the tail of the odd list.
class Solution {
public:
ListNode * oddEvenList(ListNode * head) {
// write your code here
if (!head || !head->next)
return head;
ListNode odd, even, *iterator, *odd_it, *even_it;
iterator = head;
odd_it = &odd;
even_it = &even;
int count = 1;
while (iterator) {
if (count % 2 != 0) {
odd_it->next = iterator;
odd_it = odd_it->next;
}
else {
even_it->next = iterator;
even_it = even_it->next;
}
count ++;
iterator = iterator->next;
}
even_it->next = nullptr;
odd_it->next = even.next;
return odd.next;
}
};Big O: O(N) speed, O(1) space
Tips:
Pre and cur node for single linked list. Watch out for corner cases.
class Solution {
public:
ListNode * insert(ListNode * head, int x) {
// write your code here
if (!head) {
ListNode *new_node = new ListNode(x, nullptr);
new_node->next = new_node;
return new_node;
}
ListNode *pre = nullptr, *cur = head;
do {
pre = cur;
cur = cur->next;
if (pre->val <= x && cur->val >= x)
break;
if (pre->val > cur->val && (x > pre->val || x < cur->val))
break;
} while (cur != head);
ListNode *new_node = new ListNode(x, cur);
pre->next = new_node;
return head;
}
};Big O: O(N) speed, O(1) space
Tips:
Count the nodes and count the effective move. Then rotate starting from the last node. Be careful of step = 1 case.
class Solution {
public:
ListNode * rotateRight(ListNode * head, int k) {
// write your code here
if (!head || !head->next)
return head;
int nodes_num = 1;
ListNode* iterator = head;
while (iterator->next) {
nodes_num ++;
iterator = iterator->next;
}
int effective_move = k%nodes_num;
if (effective_move == 0) return head;
iterator->next = head;
int step = nodes_num - effective_move;
while (step--) {
iterator = iterator->next;
}
ListNode *new_head = iterator->next;
iterator->next = nullptr;
return new_head;
}
};Big O: O(N) speed, O(1) space
Tips:
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode *A, *B;
int lenA{}, lenB{}, diff{};
if (!headA || !headB)
return nullptr;
A = headA;
B = headB;
while(A) {
lenA++;
A = A->next;
}
while(B) {
lenB++;
B = B->next;
}
diff = abs(lenA-lenB);
ListNode *tmp = lenA > lenB ? headA : headB;
while(diff--) tmp = tmp->next;
headA = lenA > lenB ? tmp : headA;
headB = lenB > lenA ? tmp : headB;
while(headA && headB) {
if (headA == headB) return headA;
headA = headA->next;
headB = headB->next;
}
return nullptr;
}
};Big O: O(1) speed, O(n) space
Tips:
Double linked list + hashmap
Use stl list to store the data and unordered hash map to record the position of the nodes.
#include <list>
class LRUCache {
public:
struct LRUNode {
int value;
int key;
LRUNode(int k, int v) : key(k), value(v) {}
};
LRUCache(int capacity) : cap(capacity) {}
int get(int key) {
if (!kv.count(key)) {
return -1;
}
move_front(key);
return values.front().value;
}
void set(int key, int value) {
if (!kv.count(key)) {
values.emplace_front(key, value);
kv[key] = values.begin();
if (values.size() > cap) {
kv.erase(values.back().key);
values.pop_back();
}
} else {
kv[key]->value = value;
move_front(key);
}
}
private:
int move_front(int key) {
LRUNode node = *kv[key];
values.erase(kv[key]);
values.push_front(node);
kv[key] = values.begin();
}
private:
int cap;
std::list<LRUNode> values;
std::unordered_map<int, list<LRUNode>::iterator> kv;
};Big O: O(n) speed, O(1) space
Tips:
Keep track of the last none-nine position. Create new node if none-nine position is never incremented. Then do another iteration that increment all pos >= none-nine by 1 and mod with 10.
class Solution {
public:
ListNode* plusOne(ListNode* head) {
int posNoneNine = 0;
ListNode *iterator = head, sentinal;
sentinal.next = head;
int counter = 0;
while (iterator) {
counter ++;
if (iterator->val != 9) {
posNoneNine = counter;
}
iterator = iterator->next;
}
if (posNoneNine == 0) {
ListNode *new_node = new ListNode(0, head);
sentinal.next = new_node;
}
iterator = sentinal.next;
counter = 0;
while (iterator) {
counter ++;
if (counter >= posNoneNine)
iterator->val = (iterator->val + 1)%10;
iterator = iterator->next;
}
return sentinal.next;
}
};Big O: O(1) speed, O(1) space
Tips:
Number is power of four if it is power of 2 and the set bit is at the odd bit position.
class Solution {
public:
/**
* @param num: an integer
* @return: whether the integer is a power of 4
*/
bool isPowerOfFour(int num) {
// Write your code here
if (num > 0 && ((num & (num-1)) == 0) && (0x55555555 & num))
return true;
return false;
}
};Big O: O(n) speed, O(1) space
Tips:
本题中,我们需要得到[m,n]所有元素按位与的结果。举个例子,当m=26,n=30时,它们的二进制表示为为:
11010 11011 11100 11101 11110
这个样例的答案是11000,易见我们发现我们只需要找到m和n最左边的公共部分即可。
每次都将n与n-1按位与,当n的二进制为1010时,1010 & 1001 = 1000,相当于把二进制位的最后一个1去掉了。因此我们不断的做n^n-1的操作,直到n小于m相等即可。
public class Solution {
/**
* @param m: an Integer
* @param n: an Integer
* @return: the bitwise AND of all numbers in [m,n]
*/
public int rangeBitwiseAnd(int m, int n) {
// Write your code here
while(m < n) {
n = n & (n-1);
}
return n;
}
}Big O: O(n) speed, O(1) space
Tips:
class Solution {
public:
vector<int> xorQueries(vector<int>& arr, vector<vector<int>>& queries) {
vector<int> res;
for (int i = 1; i < arr.size(); i++) {
arr[i] ^= arr[i-1];
}
for (auto &v : queries) {
if (v[0] == 0)
res.push_back(arr[v[1]]);
else {
res.push_back(arr[v[1]]^arr[v[0]-1]);
}
}
return res;
}
}Big O: O(n) speed, O(1) space
Tips:
Iterate the array first in the normal order and then in the reverse order, update the candy array in the process. Sum the candy array at the very end to get the result.
class Solution {
public:
int candy(vector<int>& ratings) {
int n = ratings.size();
if (n < 2)
return n;
vector<int>candy(n,1);
for (int i = n-2; i >= 0; i--) {
if (ratings[i] > ratings[i+1])
candy[i] = candy[i+1]+1;
}
for (int i = 1; i < n; i++) {
if (ratings[i] > ratings[i-1] && candy[i] <= candy[i-1])
candy[i] = candy[i-1]+1;
}
int res = 0;
for (int i = 0; i < n; i++) {
res += candy[i];
}
return res;
}
};Big O: O(1) speed, O(1) space
Tips:
Only need to count the prefix part of n and m.
class Solution {
public:
int rangeBitwiseAnd(int m, int n) {
while (m < n) {
n &= n - 1;
}
return m & n;
}
};Big O: O(log(n)) speed, O(1) space
Tips:
Use a temperary string to store read4 results. Be careful with situation where read4 returns with fewer than 4 bytes.
class Solution {
public:
int read(char *buf, int n) {
int read_bytes = 0, read4_bytes = 4;
char tmp_buf[4];
while (read_bytes < n && read4_bytes == 4) {
read4_bytes = read4(tmp_buf);
for (int i = 0; i < read4_bytes; i++) {
if (read_bytes >= n)
return read_bytes;
*buf++ = tmp_buf[i];
read_bytes ++;
}
}
return read_bytes;
}
};Big O: O(log(n)) speed, O(1) space
Tips:
Use private data variables to keep track of the leftover position from last call.
class Solution {
int pos = 0, read4_bytes = 0;
char tmp_buf[4];
public:
int read(char *buf, int n) {
int read_bytes = 0;
// if there is leftover
while (pos < read4_bytes && read_bytes < n) {
*buf++ = tmp_buf[pos++];
read_bytes ++;
}
while (read_bytes < n) {
read4_bytes = read4(tmp_buf);
for (pos = 0; pos < read4_bytes;) {
if (read_bytes >= n)
return read_bytes;
*buf++ = tmp_buf[pos++];
read_bytes ++;
}
if (read4_bytes != 4)
break;
}
return read_bytes;
}
};Big O: O(n) speed, O(n) space
Tips:
Use of stack. When you update the time, remember to deduce the duplicate time part of the top item in the stack.
class Solution {
struct Log {
int id;
bool isStart;
int time;
};
Log getLog(string& s) {
string id, isStart, time;
stringstream ss(s);
getline(ss, id, ':');
getline(ss, isStart, ':');
getline(ss, time, ':');
return {stoi(id), isStart == "start", stoi(time)};
}
public:
vector<int> exclusiveTime(int n, vector<string>& logs) {
vector<int> exclusive(n, 0);
stack<Log> s;
for(auto& log: logs) {
Log l = getLog(log);
if(l.isStart)
s.push(l);
else {
int time = l.time - s.top().time + 1;
exclusive[l.id] += time;
s.pop();
if(!s.empty())
exclusive[s.top().id] -= time;
}
}
return exclusive;
}
};Big O: O(n) speed, O(1) space
Tips:
Convert int to string and then work on the string.
class Solution {
public:
/**
* @param a: A number
* @return: Returns the maximum number after insertion
*/
int InsertFive(int a) {
// write your code here
int sign = a < 0;
string num = to_string(abs(a));
int n = num.size();
int i;
for (i = 0; i < n; i++) {
if (sign) {
if (num[i] - '0' > 5) {
num.insert(i, "5");
break;
}
} else {
if (num[i] - '0' < 5) {
num.insert(i, "5");
break;
}
}
}
if (i == n)
num += "5";
return sign ? -(stoi(num)) : stoi(num);
}
};Big O: O(n) speed, O(1) space
Tips:
Be careful of the indexing
class Solution {
public:
string convertToTitle(int n) {
// write your code here
string res = "";
while(n) {
int rem = (n-1)%26;
char c = rem + 'A';
res = c + res;
n = (n-1)/26;
}
return res;
}
};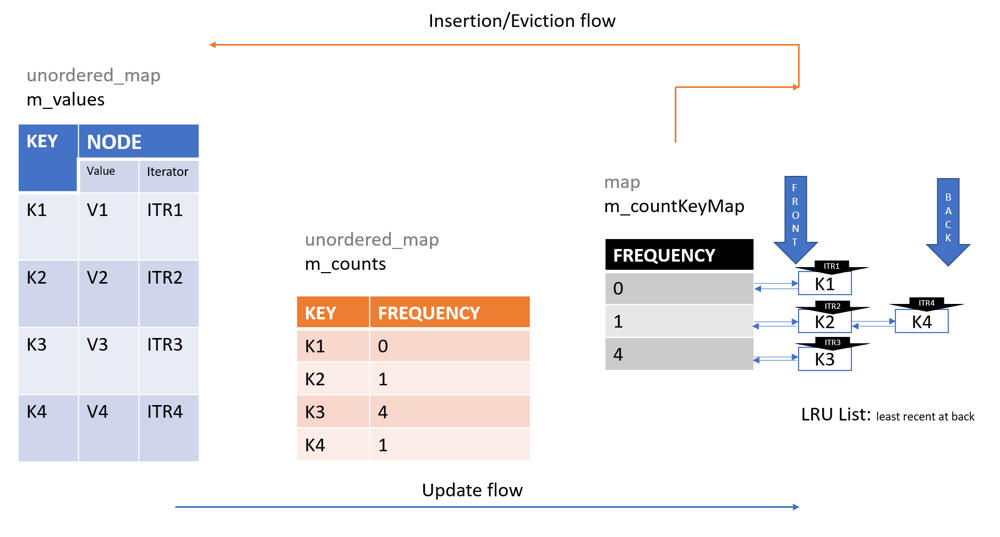
//Just for better readability
typedef int Key_t;
typedef int Count_t;
struct Node
{
int value;
list<Key_t>::iterator itr;
};
class LFUCache
{
unordered_map<Key_t, Node> m_values;
unordered_map<Key_t, Count_t> m_counts;
unordered_map<Count_t, list<Key_t>> m_countKeyMap;
int m_lowestFrequency;
int m_maxCapacity;
public:
LFUCache(int capacity)
{
m_maxCapacity = capacity;
m_lowestFrequency = 0;
}
int get(int key)
{
if (m_values.find(key) == m_values.end() || m_maxCapacity <= 0)
{
return -1;
}
//update frequency, & return value
put(key, m_values[key].value);
return m_values[key].value;
}
void put(int key, int value)
{
if (m_maxCapacity <= 0)
{
return;
}
//If key is not present and capacity has exceeded,
//then remove the key entry with least frequency
//else just make the new key entry
if (m_values.find(key) == m_values.end())
{
if (m_values.size() == m_maxCapacity)
{
int keyToDelete = m_countKeyMap[m_lowestFrequency].back();
m_countKeyMap[m_lowestFrequency].pop_back();
if (m_countKeyMap[m_lowestFrequency].empty())
{
m_countKeyMap.erase(m_lowestFrequency);
}
m_values.erase(keyToDelete);
m_counts.erase(keyToDelete);
}
m_values[key].value = value;
m_counts[key] = 0;
m_lowestFrequency = 0;
m_countKeyMap[m_counts[key]].push_front(key);
m_values[key].itr = m_countKeyMap[0].begin();
}
//Just update value and frequency
else
{
m_countKeyMap[m_counts[key]].erase(m_values[key].itr);
if (m_countKeyMap[m_counts[key]].empty())
{
if (m_lowestFrequency == m_counts[key])
m_lowestFrequency++;
m_countKeyMap.erase(m_counts[key]);
}
m_values[key].value = value;
m_counts[key]++;
m_countKeyMap[m_counts[key]].push_front(key);
m_values[key].itr = m_countKeyMap[m_counts[key]].begin();
}
}
};Big O: O(n) speed, O(1) space
Tips:
Two pointer
class Solution {
public:
int trap(vector<int>& height)
{
int ans = 0;
int left = 0, right = height.size()-1;
int left_max, right_max;
left_max = right_max = 0;
while (left < right) {
right_max = max(right_max, height[right]);
if (height[left] < height[right]) {
if (left_max > height[left]) {
ans += (left_max - height[left]);
} else {
left_max = height[left];
}
left ++;
} else {
if (right_max > height[right]) {
ans += (right_max - height[right]);
} else {
right_max = height[right];
}
right --;
}
}
return ans;
}
};Big O: O(n) speed, O(1) space
Tips:
若两个字符串长度相差大于1或相等,直接返回false。
反之,顺序判断每一位是否相等,若不相等,执行修改操作。
最后判断一下即可。
class Solution {
public:
/**
* @param s a string
* @param t a string
* @return true if they are both one edit distance apart or false
*/
bool isOneEditDistance(string& s, string& t) {
// Write your code here
int m = s.size();
int n = t.size();
if (m > n)
return isOneEditDistance(t, s);
if (n - m > 1 || s == t)
return false;
for (int i = 0; i < m; i++) {
if (s[i] != t[i]) {
if (m == n) {
s[i] = t[i];
} else {
s.insert(i, 1, t[i]);
}
break;
}
}
return s == t || s + t[n - 1] == t;
}
};Big O: O(n) speed, O(1) space
Tips:
注意 n 可能是负数, 需要求一下倒数, 可以在一开始把x转换成倒数, 也可以到最后再把结果转换为倒数.
那么现在我们实现 pow(x, n), n 是正整数的版本:
二分即可: 有 x^n = x{n/2} * x{n/2}x
n
=xn/2∗xn/2, 因此可以在 O(logn) 的时间复杂度内实现.
又叫快速幂. 有递归实现和循环实现的版本.
// Loop Version
class Solution {
private:
double _myPow(double x, long long n) {
double res = 1.0;
for (double i = x; n; n /= 2, i *= i) {
if (n % 2)
res *= i;
}
return res;
}
public:
/**
* @param x: the base number
* @param n: the power number
* @return: the result
*/
double myPow(double x, int n) {
return n < 0 ? 1.0 / _myPow(x, -n) : _myPow(x, n);
}
};
// Recursion version
class Solution {
private:
double _myPow(double x, long long n) {
// 使用long long以避免 -2147483648 边界数据出错
if (n == 0)
return 1.0;
double half = _myPow(x, n / 2);
if (n % 2)
return half * half * x;
else
return half * half;
}
public:
/**
* @param x: the base number
* @param n: the power number
* @return: the result
*/
double myPow(double x, int n) {
return n < 0 ? 1.0 / _myPow(x, -n) : _myPow(x, n);
}
};Big O: O(n) speed, O(1) space
Tips:
serialize()采用bfs,对当前二叉树搜索,遍历vector,将当前节点左右儿子依次存入vector,空节点需要删去。
deserialize()首先切割字符串,然后用isLeftChild标记是当前是左右儿子,数字转化为字符串,存为队列首节点的左右儿子。
class Solution {
public:
/**
* This method will be invoked first, you should design your own algorithm
* to serialize a binary tree which denote by a root node to a string which
* can be easily deserialized by your own "deserialize" method later.
*/
vector<string> split(const string &str, string delim) {
vector<string> results;
int lastIndex = 0, index;
while ((index = str.find(delim, lastIndex)) != string::npos) {
results.push_back(str.substr(lastIndex, index - lastIndex));
lastIndex = index + delim.length();
}
if (lastIndex != str.length()) {
results.push_back(str.substr(lastIndex, str.length() - lastIndex));
}
return results;
}
string serialize(TreeNode *root) {
if (root == NULL) {
return "{}";
}
vector<TreeNode *> q;
q.push_back(root);
for(int i = 0; i < q.size(); i++) {
TreeNode * node = q[i];
if (node == NULL) {
continue;
}
q.push_back(node->left);
q.push_back(node->right);
}
while (q[q.size() - 1] == NULL) {
q.pop_back();
}
string sb="";
sb += "{";
sb += to_string(q[0]->val);
for (int i = 1; i < q.size(); i++) {
if (q[i] == NULL) {
sb += (",#");
}
else {
sb += ",";
sb += to_string(q[i]->val);
}
}
sb += "}";
return sb;
}
/**
* This method will be invoked second, the argument data is what exactly
* you serialized at method "serialize", that means the data is not given by
* system, it's given by your own serialize method. So the format of data is
* designed by yourself, and deserialize it here as you serialize it in
* "serialize" method.
*/
TreeNode * deserialize(string &data) {
// write your code here
if (data == "{}") return NULL;
vector<string> vals = split(data.substr(1, data.size() - 2), ",");
TreeNode *root = new TreeNode(atoi(vals[0].c_str()));
queue<TreeNode *> Q;
Q.push(root);
bool isLeftChild= true;
for (int i = 1; i < vals.size(); i++) {
if (vals[i] != "#") {
TreeNode *node = new TreeNode(atoi(vals[i].c_str()));
if (isLeftChild) Q.front()->left = node;
else Q.front()->right = node;
Q.push(node);
}
if (!isLeftChild) {
Q.pop();
}
isLeftChild = !isLeftChild;
}
return root;
}
};Big O: O(n) speed, O(1) space
Tips:
Recursion
class Solution {
public:
vector<string> letterCasePermutation(string S) {
vector<string> res;
helper(S, res, {}, 0);
return res;
}
// 利用回溯法找到所有的字符串
void helper(const string S, vector<string>& res, string path, int start) {
if (start == S.size()) {
res.push_back(path);
return;
}
if (S[start] >= '0' && S[start] <= '9') {
helper(S, res, path + S[start], start + 1);
} else {
helper(S, res, path + (char)toupper(S[start]), start + 1);
helper(S, res, path + (char)tolower(S[start]), start + 1);
}
}
};Big O: O(n) speed, O(1) space
Tips:
Stack
class Solution {
public:
bool isValid(string s) {
stack<char> str;
for (auto c : s) {
if (c == '(' || c == '[' || c == '{')
str.push(c);
else if (c == ')' || c == ']' || c == '}') {
if (str.empty()) return false;
switch (c) {
case ')':
if (str.top() != '(') return false;
break;
case ']':
if (str.top() != '[') return false;
break;
case '}':
if (str.top() != '{') return false;
break;
default:
break;
}
str.pop();
}
}
return str.empty();
}
};Big O: O(n) speed, O(1) space
Tips:
Sliding window
class Solution {
public:
string countAndSay(int n) {
string res = "1";
for (int i = 2; i <= n; i++) {
string tmp = "";
char c = res[0];
int count = 1;
for (int j = 1; j < res.size(); j++) {
if (res[j] != c) {
tmp.push_back('0' + count);
tmp.push_back(c);
count = 0;
c = res[j];
}
count ++;
}
tmp.push_back('0' + count);
tmp.push_back(c);
res = tmp;
}
return res;
}
};Big O: O(n) speed, O(1) space
Tips:
Compare neighboring intervals one by one
class Solution {
public:
/**
* @param intervals: interval list.
* @return: A new interval list.
*/
vector<Interval> merge(vector<Interval> &intervals) {
// write your code here
if (intervals.size() < 2) return intervals;
sort(intervals.begin(), intervals.end(), [](Interval &a, Interval &b){ return a.start < b.start;});
vector<Interval> ans;
for (auto &inte : intervals) {
if (ans.empty())
ans.push_back(inte);
else {
int sz = ans.size();
if (ans[sz-1].end < inte.start)
ans.push_back(inte);
else {
ans[sz-1].end = ans[sz-1].end > inte.end ? ans[sz-1].end : inte.end;
}
}
}
return ans;
}
};Big O: O(n) speed, O(1) space
Tips:
Let's start from empty subset in output list. At each step one takes new integer into consideration and generates new subsets from the existing ones.
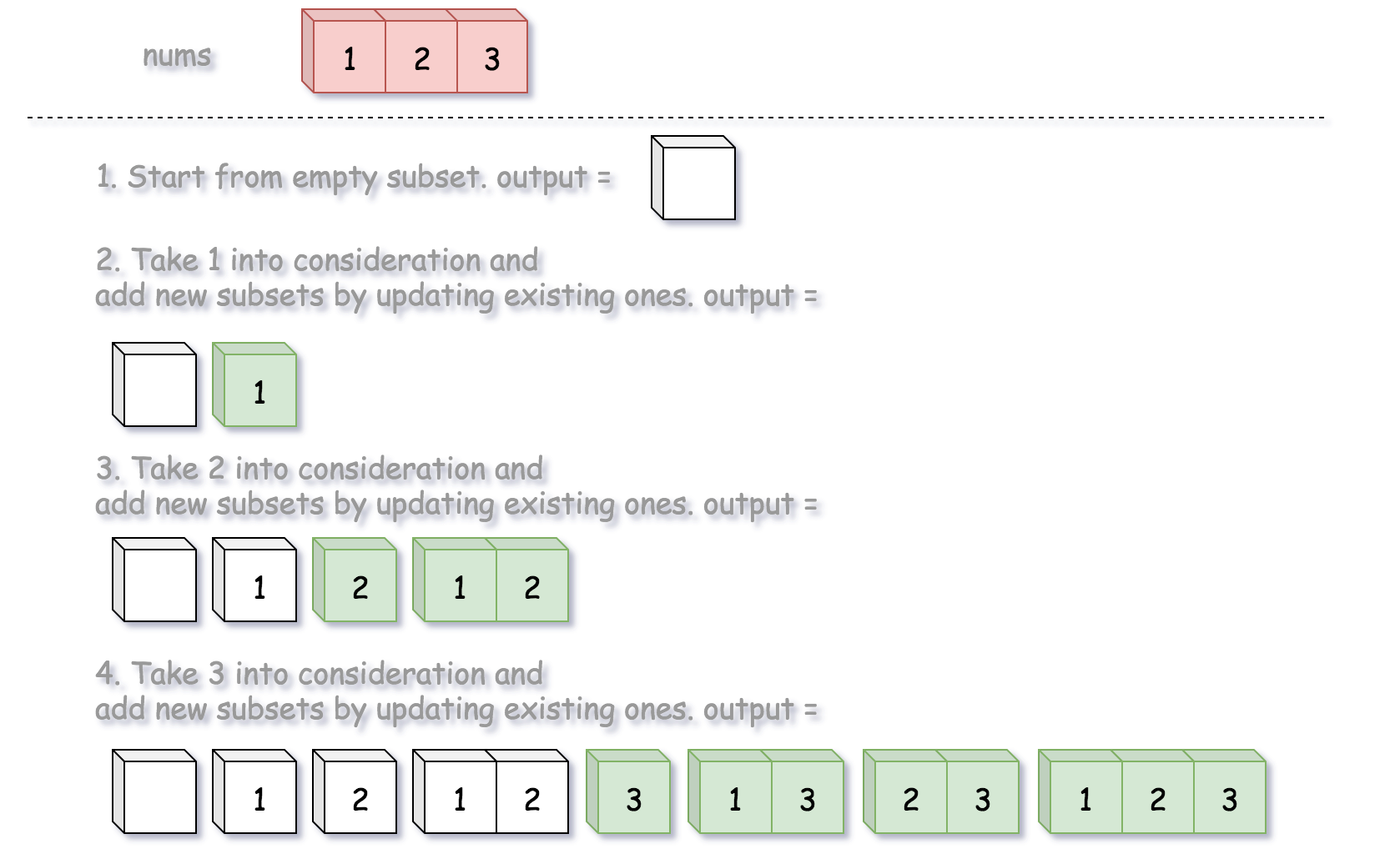
class Solution {
public:
static vector<vector<int>> subsets(const vector<int>& nums) {
vector<vector<int>> subsets;
subsets.push_back(vector<int>());
for (auto num : nums) {
int n = subsets.size();
for (int i = 0; i < n; i++) {
vector<int> new_set(subsets[i]);
new_set.push_back(num);
subsets.push_back(new_set);
}
}
return subsets;
}
};Big O: O(n) speed, O(1) space
Tips:
Let's start from empty subset in output list. At each step one takes new integer into consideration and generates new subsets from the existing ones.
Big O: O(n) speed, O(1) space
Tips:
Compare Adjacent Words.
class Solution {
public:
bool isAlienSorted(vector<string>& words, string order) {
for (int i = 0; i < words.size() - 1; i++) {
string word1 = words[i];
string word2 = words[i + 1];
int i1 = 0, i2 = 0;
while (word1[i1] == word2[i2]) {
i1++, i2++;
}
int r = order.find(word1[i1]);
int s = order.find(word2[i2]);
if (r > s) return false;
}
return true;
}
};Big O: O(n) speed, O(1) space
Tips:
Two pointers.
class Solution {
public:
int maxArea(vector<int>& height) {
int max_a = 0;
int st = 0, end = height.size()-1;
while (st < end) {
int water = min(height[st], height[end]) * (end-st);
max_a = max(max_a, water);
if (height[st] < height[end])
st ++;
else
end --;
}
return max_a;
}
};Big O: O(n) speed, O(1) space
Tips:
Keep a lastzero index record.
class Solution {
public:
void moveZeroes(vector<int>& nums) {
int lastNonZeroFoundAt = 0;
// If the current element is not 0, then we need to
// append it just in front of last non 0 element we found.
for (int i = 0; i < nums.size(); i++) {
if (nums[i] != 0) {
nums[lastNonZeroFoundAt++] = nums[i];
}
}
// After we have finished processing new elements,
// all the non-zero elements are already at beginning of array.
// We just need to fill remaining array with 0's.
for (int i = lastNonZeroFoundAt; i < nums.size(); i++) {
nums[i] = 0;
}
}
};Big O: O(n) speed, O(1) space
Tips:
Use Xor
class Solution {
public:
int findComplement(int num) {
int bit = 1, tp = num;
while(tp) {
num ^= bit;
bit <<= 1;
tp >>= 1;
}
return num;
}
};Big O: O(n) speed, O(1) space
Tips:
Using Cumulative Sum
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
int count = 0, sum = 0;
unordered_map<int, int> m;
m[0] = 1;
for (int i=0; i<nums.size(); i++) {
sum += nums[i];
if (m.find(sum - k) != m.end())
count += m[sum - k];
m[sum]++;
}
return count;
}
};Big O: O(n) speed, O(1) space
Tips:
We are going to use a two pointer approach to solve this.
The idea here is that
1. We will store the characters of t in a map lets say mapt.
2. We will have two pointers l and r.
3. Whille we traverse through s we check if the character is found in mapt If so we will store the character into another hash map lets say maps.
4. If the mapped charcter freq of s is less than or equal to mapt we increment a letter counter variable that will let us know when we have reached the t string size.
5. We try to find the smallest substring which contains all chracters in t using a while loop.
S = "ADOBECODEBANC" and T = "ABC"
string minWindow(string s, string t) {
unordered_map<char,int> map1;
unordered_map<char,int> map2;
int check=INT_MAX;
string result;
for(char &ch:t)map1[ch]++;
int slow=0,fast=0,lettercounter=0;
for(;fast<s.length();fast++)
{
char ch=s[fast];
if(map1.find(ch)!=map1.end())
{
map2[ch]++;
if(map2[ch]<=map1[ch])
lettercounter++;
}
if(lettercounter>=t.length())
{
while(map1.find(s[slow])==map1.end()||map2[s[slow]]>map1[s[slow]])
{
map2[s[slow]]--;
slow++;
}
if(fast-slow+1<check)
{
check=fast-slow+1;
result=s.substr(slow,check);
}
}
}
return result;
}Big O: O(n) speed, O(1) space
Tips:
Quick Select
class Solution {
public:
int findKthLargest(vector<int>& nums, int k) {
//partition rule: >=pivot pivot <=pivot
int left=0,right=nums.size()-1,idx=0;
while(1){
idx = partition(nums,left,right);
if(idx==k-1) break;
else if(idx < k-1) left=idx+1;
else right= idx-1;
}
return nums[idx];
}
int partition(vector<int>& nums,int left,int right){//hoare partition
int pivot = nums[left], l=left+1, r = right;
while(l<=r){
if(nums[l]<pivot && nums[r]>pivot) swap(nums[l++],nums[r--]);
if(nums[l]>=pivot) ++l;
if(nums[r]<=pivot) --r;
}
swap(nums[left], nums[r]);
return r;
}
};Big O: O(n) speed, O(n) space
Tips:
Hashmap
class Solution {
public:
vector<int> countduplicates(vector<int> &nums) {
// write your code here
unordered_map<int, bool> dup;
vector<int> ans;
for (auto n : nums) {
if ((dup.find(n) != dup.end()) && !dup[n]) {
ans.push_back(n);
dup[n] = true;
}
else if (dup.find(n) == dup.end())
dup[n] = false;
}
return ans;
}
};Big O: O(n^2) speed, O(1) space
Tips:
Sort + 2 Sum II (two pointer).
Be careful with duplicate items.
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
sort(begin(nums), end(nums));
vector<vector<int>> res;
for (int i = 0; i < nums.size() && nums[i] <= 0; ++i)
if (i == 0 || nums[i - 1] != nums[i]) {
twoSumII(nums, i, res);
}
return res;
}
void twoSumII(vector<int>& nums, int i, vector<vector<int>> &res) {
int lo = i + 1, hi = nums.size() - 1;
while (lo < hi) {
int sum = nums[i] + nums[lo] + nums[hi];
if (sum < 0) {
++lo;
} else if (sum > 0) {
--hi;
} else {
res.push_back({ nums[i], nums[lo++], nums[hi--] });
while (lo < hi && nums[lo] == nums[lo - 1])
++lo;
}
}
}
};Big O: O(n) speed, O(1) space
Tips:
Two pointers pre and cur.
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
ListNode sentinal, *pre, *cur, *nxt;
sentinal.next = head;
sentinal.val = INT_MIN;
pre = &sentinal;
cur = pre;
while (cur && cur->next) {
while (cur->next && cur->val == cur->next->val) {
cur = cur->next;
}
cur = cur->next;
pre->next = cur;
if (cur && cur->next && cur->val != cur->next->val)
pre = pre->next;
}
return sentinal.next;
}
};Big O: O(L) speed, O(1) space
Tips:
One pass algorithm:
The first pointer advances the list by n+1n+1 steps from the beginning, while the second pointer starts from the beginning of the list. Now, both pointers are exactly separated by nn nodes apart. We maintain this constant gap by advancing both pointers together until the first pointer arrives past the last node. The second pointer will be pointing at the nnth node counting from the last. We relink the next pointer of the node referenced by the second pointer to point to the node's next next node.
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
if (head == nullptr || (head->next == nullptr && n > 0))
return nullptr;
ListNode sentinal, *first, *second;
sentinal.next = head;
first = &sentinal;
second = &sentinal;
while(n--) {
if (second == nullptr)
return nullptr;
second = second->next;
}
while(second->next) {
first = first->next;
second = second->next;
}
first->next = first->next->next;
return sentinal.next;
}
};Big O: O(log(n)) speed, O(1) space
Tips:
Recursion.
class Solution {
public:
/**
* @param root: root of the given tree
* @return: whether it is a mirror of itself
*/
bool isSymmetric (TreeNode* root) {
// Write your code here
return root == nullptr || isSymmetricHelp (root->left, root->right);
}
bool isSymmetricHelp (TreeNode* left, TreeNode* right) {
if (left == nullptr || right == nullptr) {
return left == nullptr && right == nullptr;
}
if (left->val != right->val) {
return false;
}
return isSymmetricHelp (left->left, right->right) && isSymmetricHelp (left->right, right->left);
}
};Big O: O(N) speed, O(1) space
Tips:
Counting Repeating Bits. If the mod with 3 is one, then that number must have this bit set.
class Solution {
public:
void count_bits(int arr[], int val) {
for (int i = 0; i < 32; i++) {
if (val & (0x1 << i))
arr[i] ++;
}
}
int singleNumber(vector<int>& nums) {
int arr[32] = {};
int ret = 0;
for (auto num : nums) {
count_bits(arr, num);
}
for (int i = 0; i < 32; i++) {
arr[i] = arr[i]%3;
ret |= (arr[i] << i);
}
return ret;
}
};Big O: O(N) speed, O(1) space
Tips:
Counting Repeating Bits. If the bit position appears more than n/2 times, then we know it is for sure in the number.
class Solution {
public:
int majorityElement(vector<int>& nums) {
int n = nums.size();
int ans = 0, bits[32] = {0};
for (auto num : nums) {
for (int i = 0; i < 32; i++) {
bits[i] += ((num >> i) & 0x1);
}
}
for (int i = 0; i < 32; i++) {
if (bits[i] > n/2)
ans |= (1U << i);
}
return ans;
}
};Big O: O(N) speed, O(1) space
Tips:
First record all the last occurance indexes of each letter. Than go through the array again and partition.
class Solution {
public:
vector<int> partitionLabels(string S) {
int letters[26] = {0};
int n = S.size();
vector<int> ans;
if (n == 0)
return ans;
for (int i = 0; i < n; i++) {
// record the last occurance index of the letter
letters[S[i]-'a'] = i;
}
int p_size = letters[S[0]-'a'];
for (int i = 0; i < n; i++) {
// record the last occurance index of the letter
if (i <= p_size) {
p_size = max(letters[S[i]-'a'], p_size);
} else {
ans.push_back(p_size);
p_size = letters[S[i]-'a'];
}
}
ans.push_back(p_size);
for (int i = ans.size()-1; i >= 1; i--) {
ans[i] = ans[i] - ans[i-1];
}
ans[0] += 1;
return ans;
}
};Big O: O(N^2 or N^3) speed, O(1) space
Tips:
DP method:
To improve over the brute force solution, we first observe how we can avoid unnecessary re-computation while validating palindromes. Consider the case "ababa". If we already knew that "bab" is a palindrome, it is obvious that "ababa" must be a palindrome since the two left and right end letters are the same.
p(i, j) if substring Si...Sj is panlidrome.
Therefore:
p(i, j) = (p(i+1, j-1) && Si == Sj)
Base cases:
p(i, i) = true
p(i, i+1) = (Si == S_(i+1))
//Brutal Force
class Solution {
public:
bool isPanlidrome(string &s, int st, int end) {
while (st < end) {
if (s[st++] != s[end--])
return false;
}
return true;
}
string longestPalindrome(string s) {
int n = s.size();
string ans = "";
for (int i = 0; i < n; i++) {
int st = i, end = n-1;
while (st <= end) {
// if it is guanranteed that ans has bigger size, go to the next index
if ((end - st + 1) <= ans.size()) {
break;
} else if (s[st] == s[end]){
if (isPanlidrome(s, st, end)) {
ans = s.substr(st, end-st+1);
}
} else {
end --;
}
}
}
return ans;
}
};
// DP solution
string longestPalindrome(string s) {
const int n = s.size();
if(n==0) return "";
int dp[n][n], maxlen =1 , left=0;// maxlen = 1 when only one word
memset(dp,0,n*n*sizeof(int));
for(int i=0;i<n;++i){
dp[i][i] = 1;
for(int j=0;j<i;++j){
dp[j][i] = (s[j]==s[i] && (i-j< 2 || dp[j+1][i-1]));
if(dp[j][i] && maxlen < i-j+1){
left = j;
maxlen = i-j+1;
}
}
}
return s.substr(left,maxlen);
}Big O: O(M*N) speed, O(1) space
Tips:
Recursion
class Solution {
public:
bool helper(TreeNode* s, TreeNode* t) {
if (s == nullptr && t == nullptr)
return true;
if ((s == nullptr && t != nullptr) || (s != nullptr && t == nullptr))
return false;
return s->val == t->val && helper(s->left, t->left) && helper(s->right, t->right);
}
bool isSubtree(TreeNode* s, TreeNode* t) {
if ((s == nullptr && t != nullptr) || (s != nullptr && t == nullptr))
return false;
if (helper(s, t))
return true;
return isSubtree(s->left, t) || isSubtree(s->right, t);
}
};Big O: O(M*N) speed, O(1) space
Tips:
In the stack, store the pair of <new_val, current_min>.
class MinStack {
stack<pair<int, int>> data;
public:
/** initialize your data structure here. */
MinStack() {
}
void push(int val) {
int min_val = (val < getMin()) ? val : getMin();
data.push(make_pair(val, min_val));
}
void pop() {
if (!data.empty())
data.pop();
}
int top() {
pair<int, int> item = data.top();
return item.first;
}
int getMin() {
if (data.empty())
return INT_MAX;
pair<int, int> item = data.top();
return item.second;
}
};Big O: O(2^n or n^3) speed, O(1) space
Tips:
To optimize the brutal force method, we add memorizations:
In the previous approach we can see that many subproblems were redundant, i.e we were calling the recursive function multiple times for a particular string. To avoid this we can use memoization method, where an array memomemo is used to store the result of the subproblems. Now, when the function is called again for a particular string, value will be fetched and returned using the memomemo array, if its value has been already evaluated.
With memoization many redundant subproblems are avoided and recursion tree is pruned and thus it reduces the time complexity by a large factor.
// Brutal Force
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
set<string> word_set(wordDict.begin(), wordDict.end());
return wordBreakRecur(s, word_set, 0);
}
bool wordBreakRecur(string& s, set<string>& word_set, int start) {
if (start == s.length()) {
return true;
}
for (int end = start + 1; end <= s.length(); end++) {
if (word_set.find(s.substr(start, end - start)) != word_set.end() and
wordBreakRecur(s, word_set, end)) {
return true;
}
}
return false;
}
};
// Recursion with memo
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
set<string> word_set(wordDict.begin(), wordDict.end());
// In the memo table, -1 stands for the state not yet reached,
// 0 for false and 1 for true
vector<int> memo(s.length(), -1);
return wordBreakMemo(s, word_set, 0, memo);
}
bool wordBreakMemo(string& s, set<string>& word_set, int start, vector<int>& memo) {
if (start == s.length()) {
return true;
}
if (memo[start] != -1) {
return memo[start];
}
for (int end = start + 1; end <= s.length(); end++) {
if (word_set.find(s.substr(start, end - start)) != word_set.end() and
wordBreakMemo(s, word_set, end, memo)) {
return memo[start] = true;
}
}
return memo[start] = false;
}
};